Collecting data that correspond to real user interactions improves the accuracy and robustness of your bot.
Data can come from a variety of sources - when starting out, they will often come from the developer or designer working on the bot, and may be a small set of phrases that seem most obvious for potential users’ to use.
At this early stage, only a small part of the complete potential set of utterances has been captured.
As each stage progresses, the amount and depth of data will grow - during user testing it will expand with utterances from friends, colleagues and other early stage testers.
At the beta and production stages, the data sets will expand further as more real user data is incorporated. Additionally, external sources of data such as crowd-sourced services and public datasets can be leveraged to further improve the model.
As the amount of data grows, there is a divergence between test data and training data. While initially these will overlap, it is important that they be kept as independent datasets to avoid over-fitting. When overfitted, the model matches ONLY to exactly what it is trained on, instead of handling similar variations automatically.
A good rule of thumb for the ratio of training to test data is 80/20 - 80% of user data is training, 20% is reserved for testing.
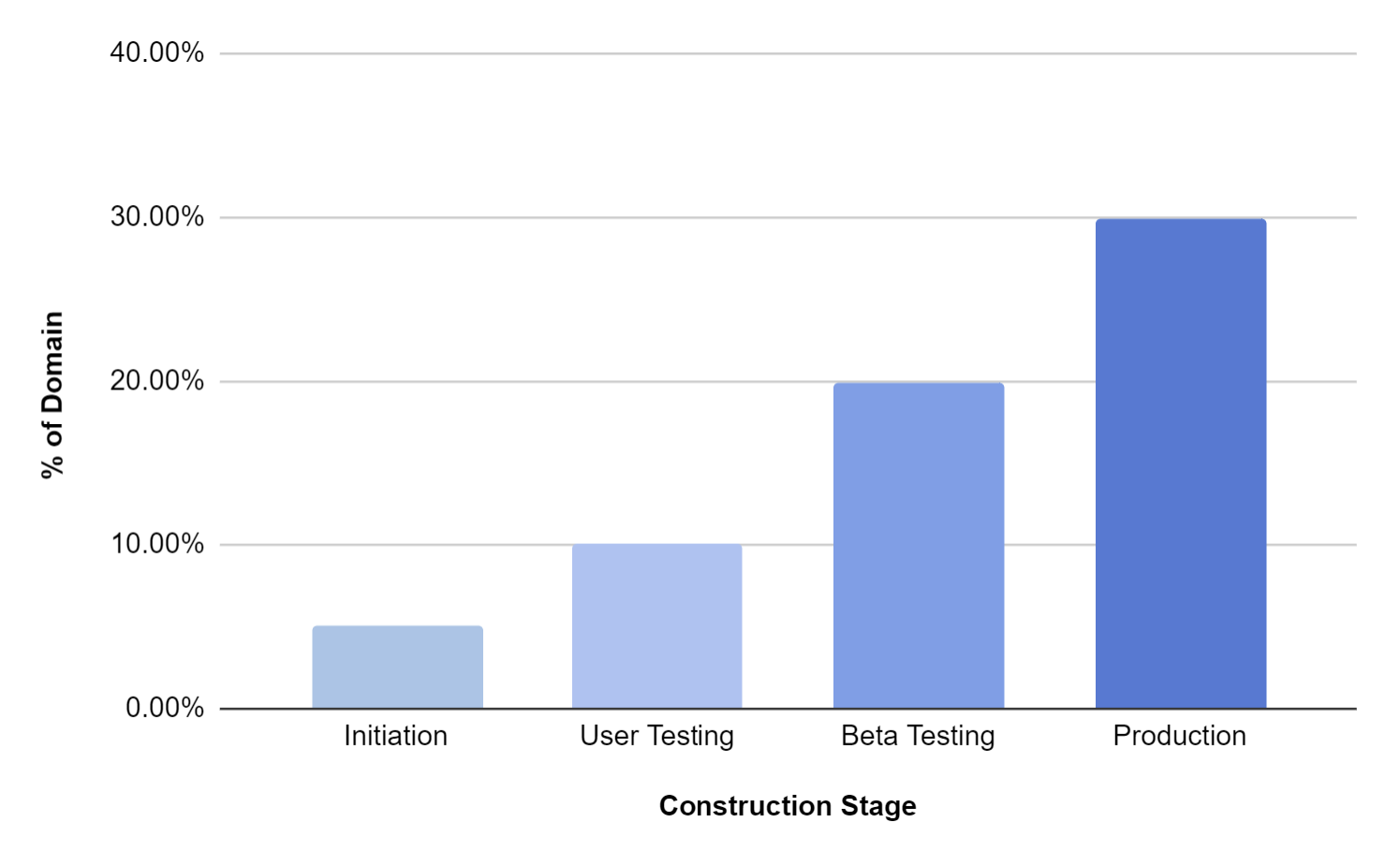
At every stage, the data collected is used to measure and train the model to improve its accuracy.